In the Part 1 I demonstrated how to obtain the data from the tracking service. I Part 2 I looked at the route choices between each control points, and in this part I will look into the activity patterns of riders.
Like in the previous analysis, the key point here is to demonstrate techniques for analyzing data that tracking services provide, although I try also to answer few questions that I am interested myself when following such event.
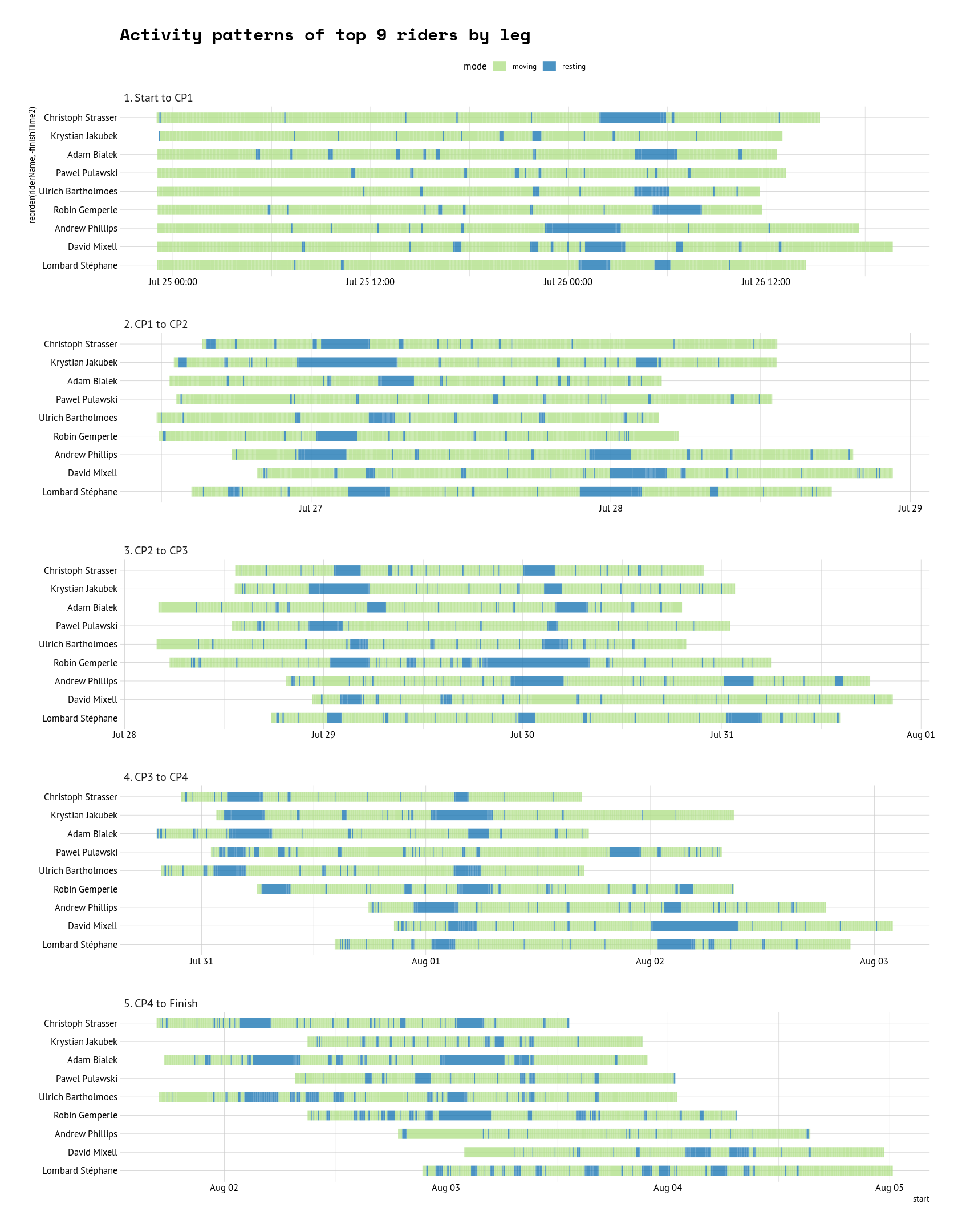
For the analysis of activity patterns we look into each segments between location points. This means that each rider has roughly 2500 of these segments between each points. We compute distance, time and average speed for each segment and through the average speed we can indirectly reason whether rider has been moving or resting in between. Data consist only location points while rider has been moving (perhaps device only logs while moving), but in this analysis a segment with average speed less than 2km/h is considered resting and is show as blue in the graph below.
Well, what can we say. The top riders slept very little.
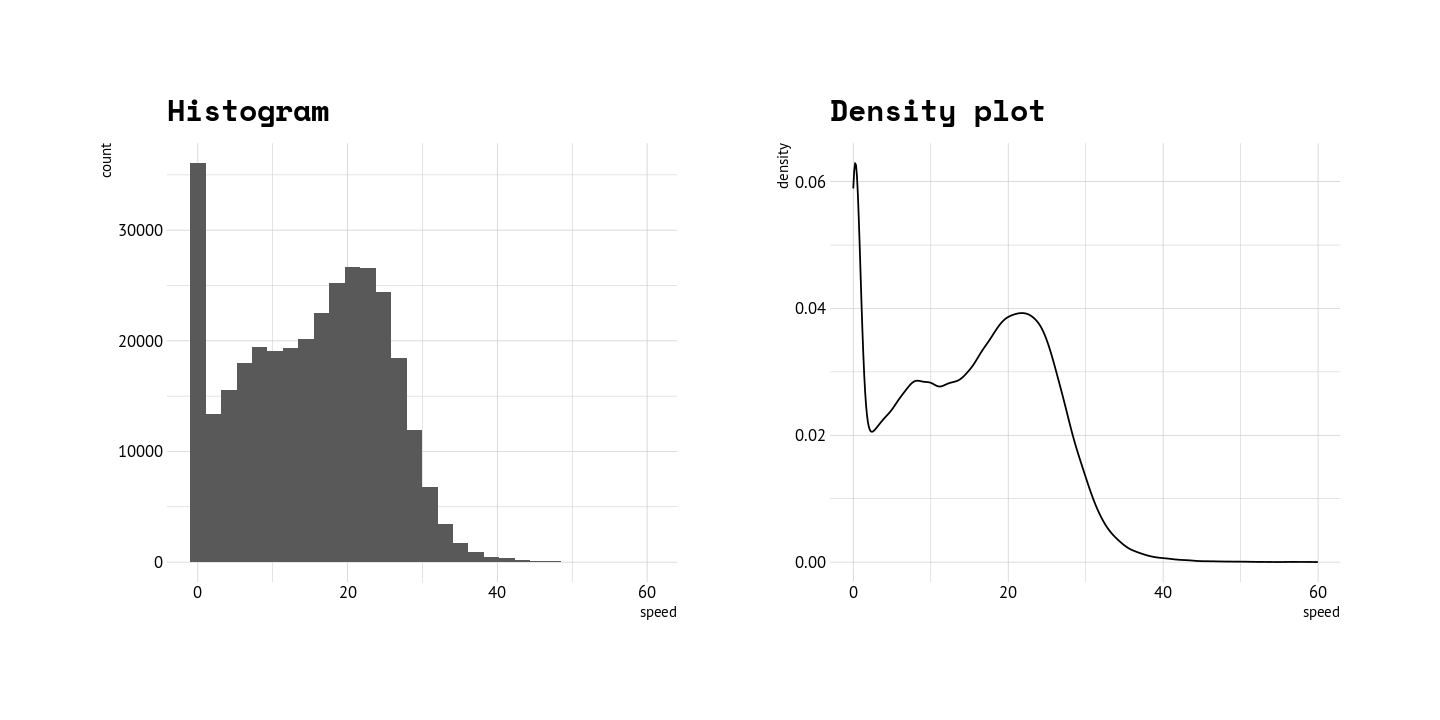
The term riding profile is used here to refer to distribution of average speeds in segments as described below. I use density plots instead of histograms to plot the distributions. (A density plot is a representation of the distribution of a numeric variable. It uses a kernel density estimate to show the probability density function of the variablemore). Density plot is good way to present overlapping distributions of subgroups ie. riders in this case.
Just to make things clear, below is a comparison of histogram and density plot.
In the plot below we have again top 9 riders and their “riding profile” of each leg. There are differences, the greatest being in the last leg when some riders had to stop and wait for the ferry.
[/kode]
ggplot(histo_dat %>%filter(!is.na(leg)) %>%filter(position_overall %in%1:9), aes(x = speed, fill = riderName)) +# geom_histogram(alpha = .5, position = position_dodge(width = 1)) +geom_density(alpha = .5) +labs(title ="Distribution of average speeds between each location points \nfor top 9 riders",subtitle ="The more to the right the distribution is the faster the rider has beenand the lower the left end of distribution is the less time riders has spent stationary") +facet_grid(riderName~leg) +xlim(c(0,40)) +theme(legend.position ="none")
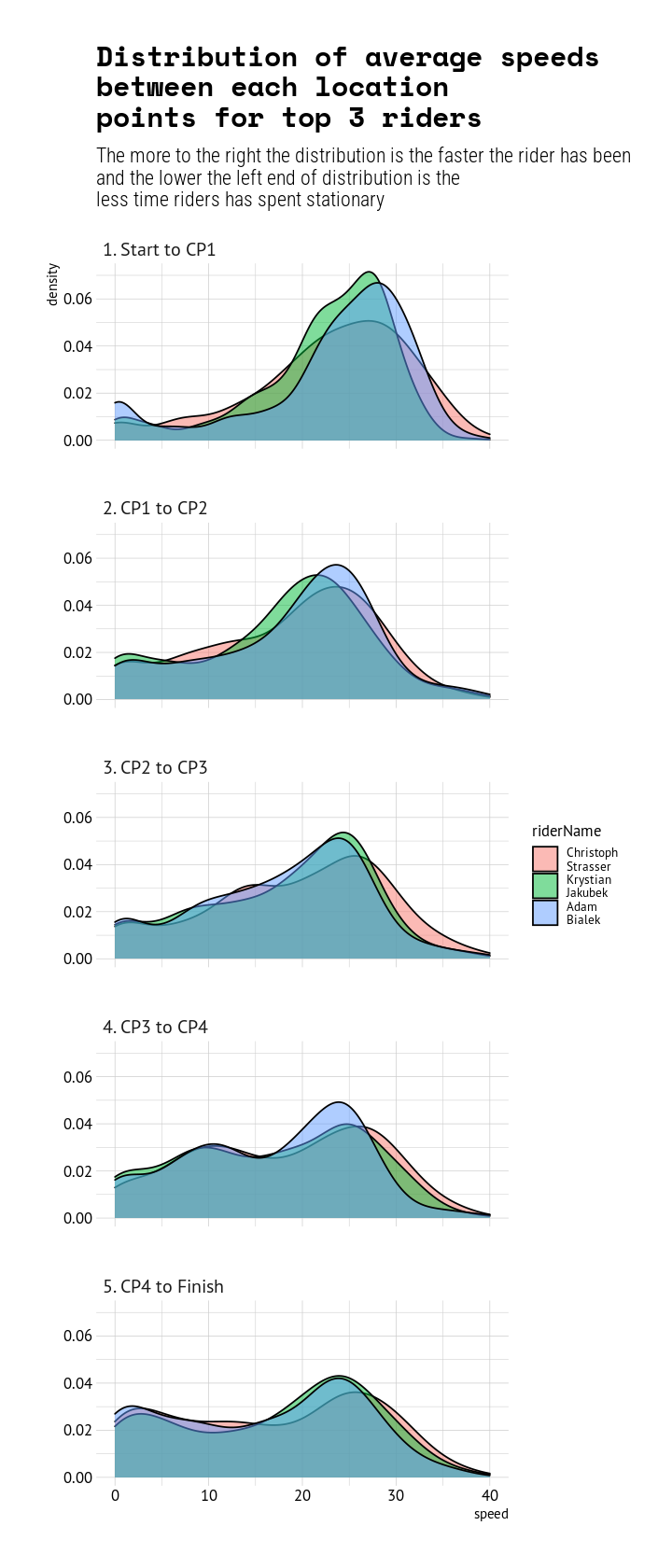
When comparing the top 3 riders, we can see that Strasser has been resting perhaps slightly less and riding tiny bit more at the top speed (>35kmh) zone.
[/kode]
ggplot(histo_dat %>%filter(!is.na(leg)) %>%filter(position_overall %in%1:3), aes(x = speed, fill = riderName)) +geom_density(alpha = .5) +labs(title ="Distribution of average speeds \nbetween each location \npoints for top 3 riders",subtitle ="The more to the right the distribution is the faster the rider has beenand the lower the left end of distribution is the less time riders has spent stationary") +facet_wrap(~leg, ncol =1) +xlim(c(0,40)) +theme(legend.position ="right")
This was all for now, I may write one more in Finnish and focus on fellow countrymen.