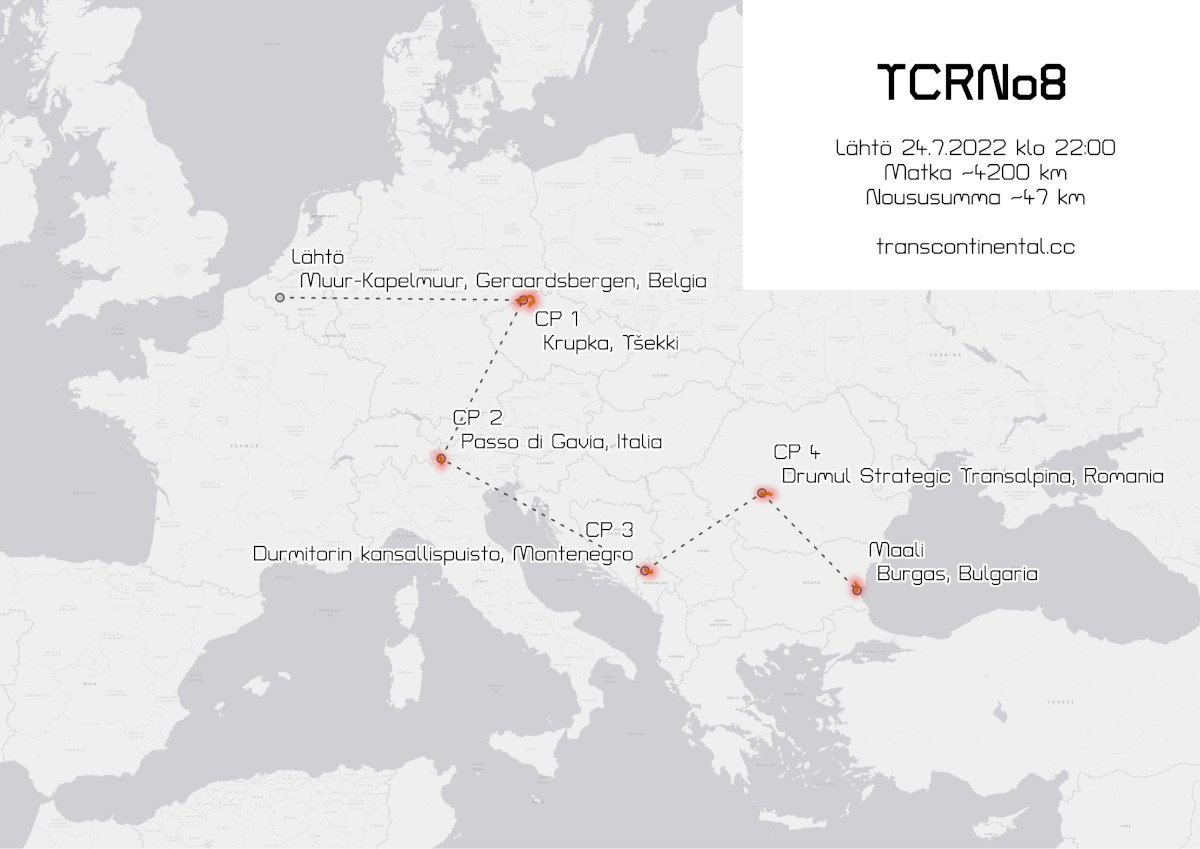
Transcontinental Race No8 (tcrno8) was ridden few weeks back in July August 2022 from Muur, Belgium to Burgas in Bulgaria. I created a “Shadow tracker” web app (not available as the race is gone) that used the data API’s of the official Follow My Challenge tracking.
This is the first part of analysis of tcrno8, and here I focus on obtaining and processing of data. I will provide code snippets in R-language for you to reproduce.
Tärkeää
Follow My Challenge does not provide details on their data licencing and therefore I won’t share any data here, only code!
Real-time mode in Follow my challenge show additional data from each rider such as distance ridden, time since last report, current speed or scratcing status. The data from the latest location can be accessed in here https://www.followmychallenge.com/live/tcrno8/data/ridersArray.json. This data also has the altitude value for that particular point, but we don’t need it as we sourced it elsewhere for the replay data.
With the following code we can get the latest tracking data and join that with longitudinal replay data.
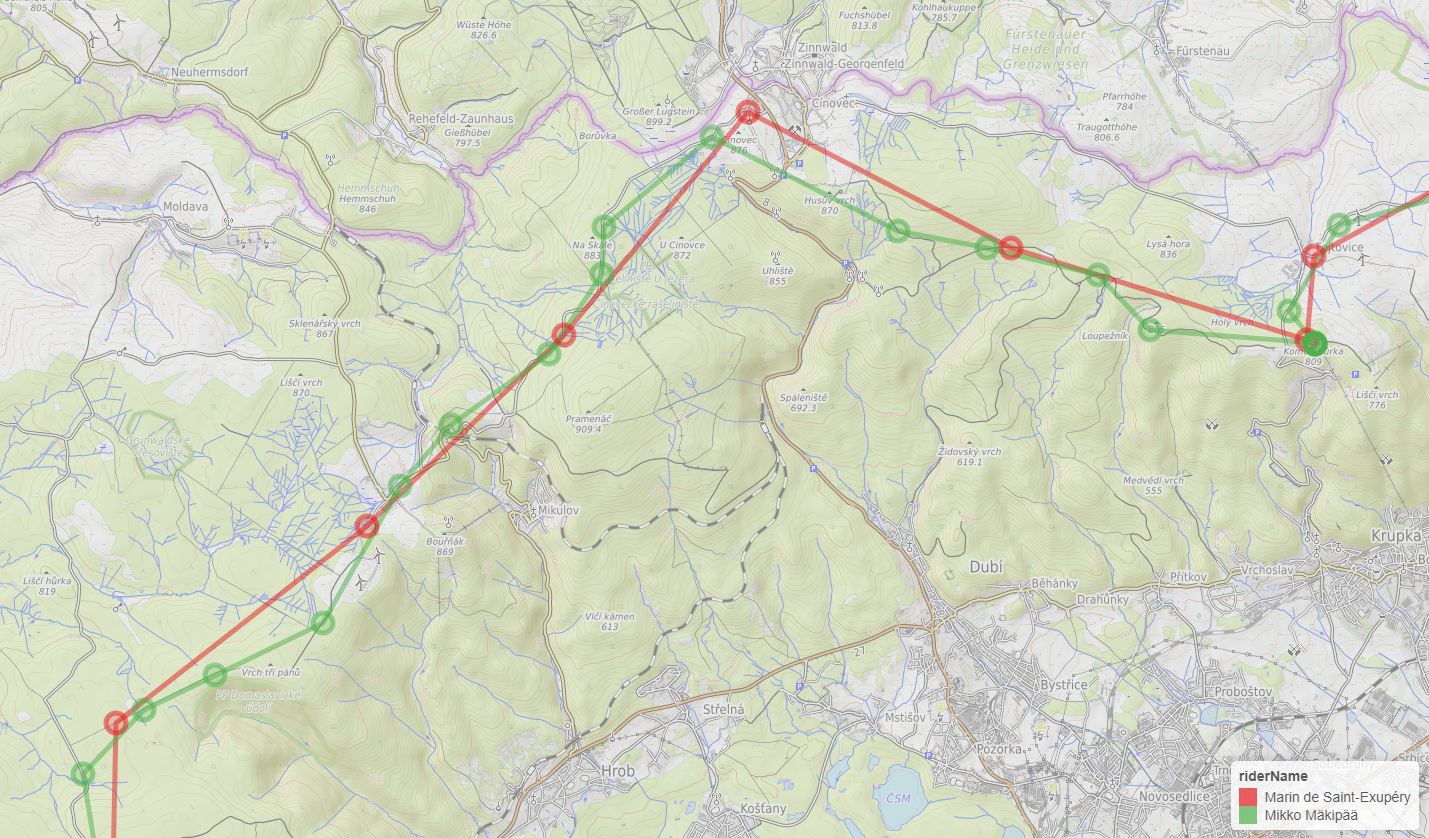
Replay data from Follow my route is far from perfect. There seems to be some systematic missing data from some riders, and not just due to scratching, but perhaps some device/hardware issue.
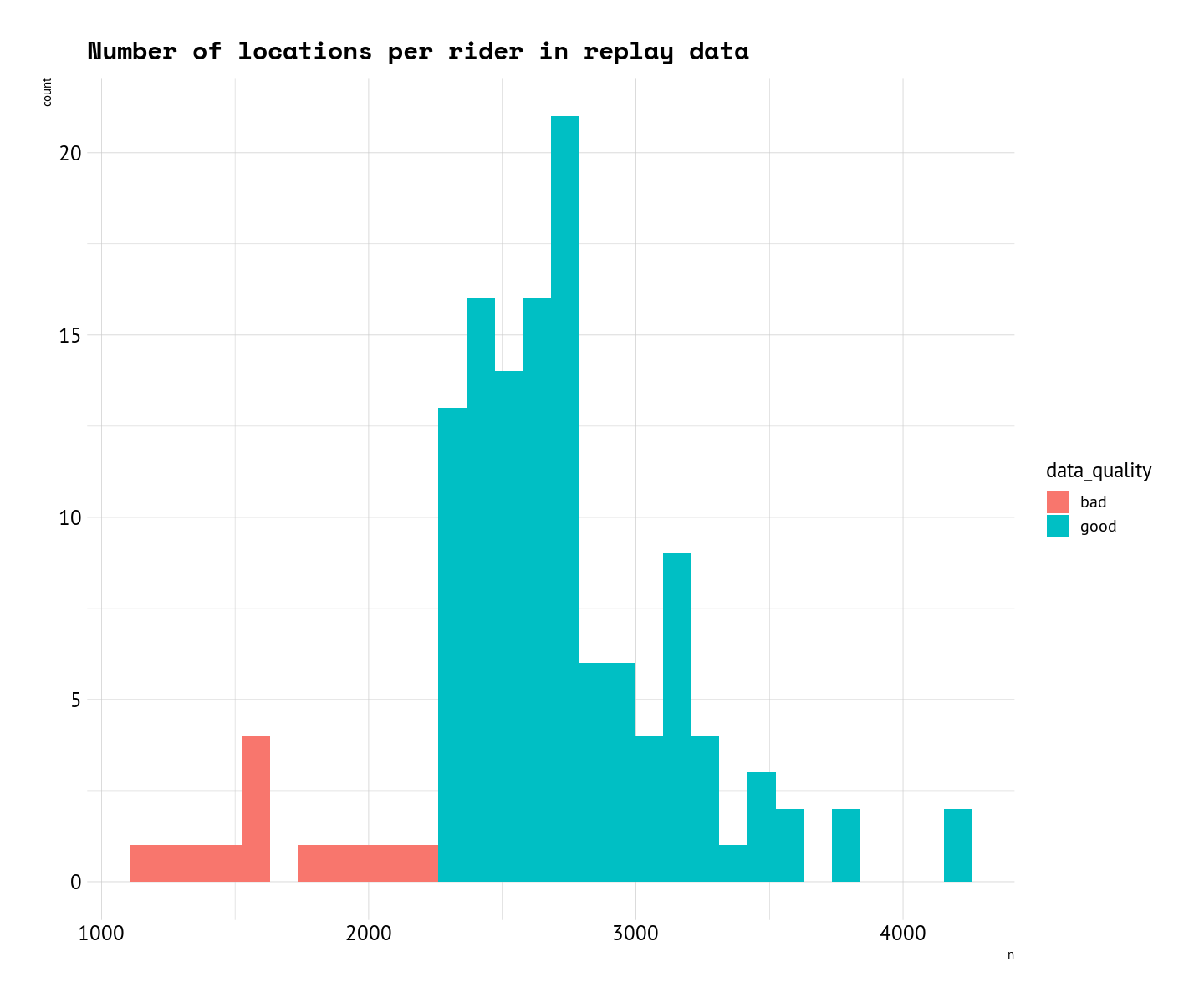
To solve this I will exclude two groups or riders: 1) scratched and 2) one with less than 2250 location points in the data.
First group is obvious, second one is based on the a breaking point in the distribution of location points. As shown in the plot below, majority of the riders have more than 2250 location points (labelled as “good” quality data). Including riders with few location points will affect the more detailed route choice or resting pattern analyses.
[/kode]
routes_and_points %>%st_drop_geometry() %>%filter(scratched ==0) %>%count(riderName) %>%arrange(n) -> nr_logs# reactable::reactable(nr_logs, searchable = TRUE)nr_logs_d <- nr_logs %>%mutate(data_quality =ifelse(n >2250, "good", "bad"))ggplot(nr_logs_d, aes(x = n, fill = data_quality)) +geom_histogram() +labs(title ="Number of locations per rider in replay data")
And here is a close-up showing how the data quality issue looks in real world.
Adding elevation
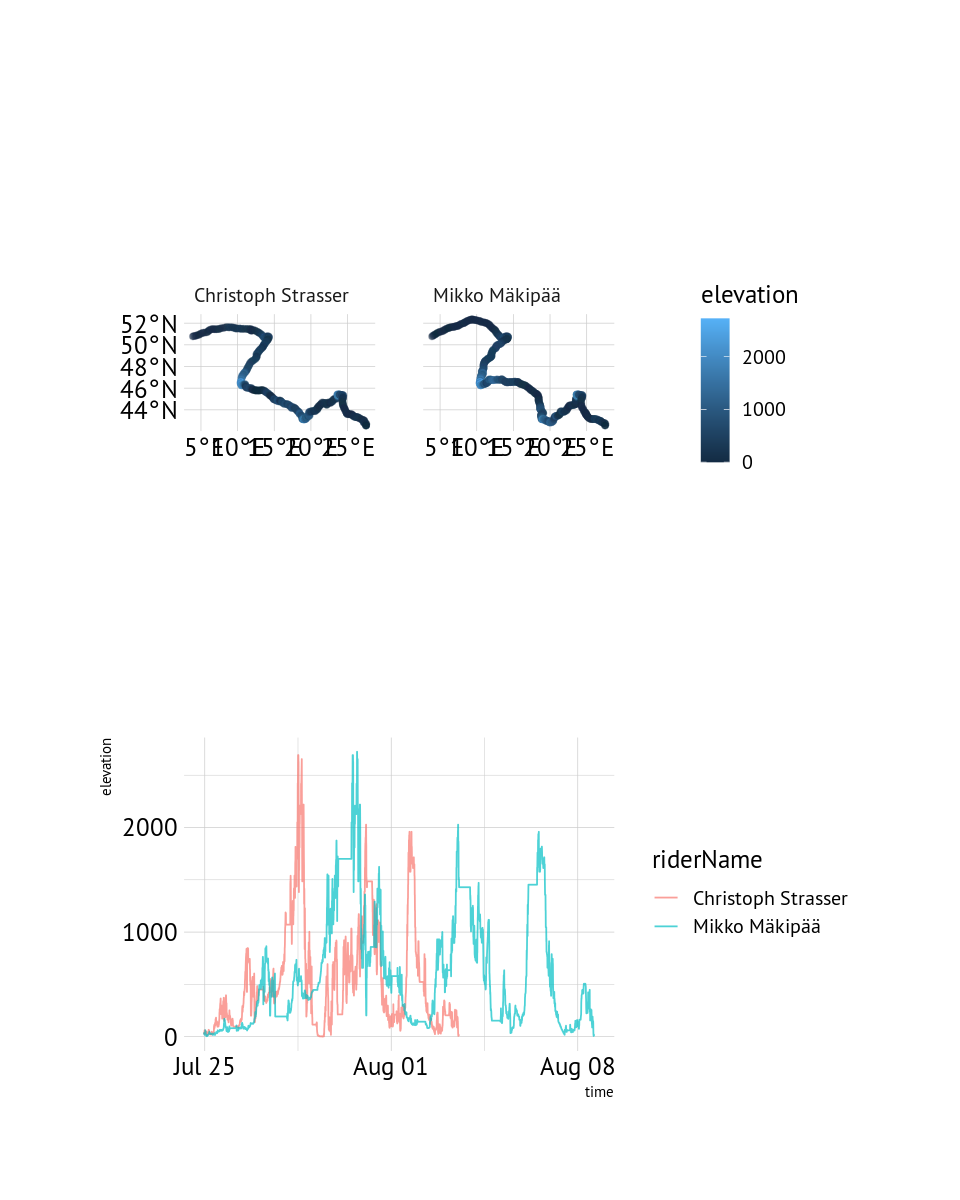
Replay data only show point location in lat/lon with time, but is missing elevation. elevatr provides functions to inteface with AWS terrain tiles to get elevation data for any location point. It is straightforward to add elevation for each location.
As a final step in this data sourcing post, we will transform the POINT data with 330693 rows in into MULTILINESTRING data with single row per rider, containing only the riders that did not scratch and whose location data is of “good quality”.